All About Recursion, PTC, TCO and STC in JavaScript
Recently everyone seems to be really excited about functional programming and its concepts. However, many people don't talk about recursion and, especially, about proper tail calls, which is really important when it comes to writing clean and concise code without exploding the stack.
In this post, I'll give you tips to better visualize and think about recursion and explain what are proper tail calls, tail call optimization, syntactic tail calls and how to differentiate them, how they work and talk about their implementation in major JavaScript engines.
I'll also be talking a lot about the call stack and stack traces, but I'll not get into too much detail, thus if you want to read more about it take a look at this blog post I've made (which, by the way, is the most popular post in this website until now).
Update - March, 5th - 2018
Please notice that Node does not support TCO/Proper Tail Calls anymore since 8.x, even behind especial flags.
However, I think this post is still very useful for learning how to thinking about recursion, visualizing it and developing mental tools to understand algorithms that involve it, so I highly recommend you to try this code using Node versions between 6.5 and 7.10.
I also recommend you to use NVM for installing and managing Node.js versions. It will make your life a lot easier.
Now, let's proceed.
Recursion in a Nutshell
Recursion happens when the solution of a problem depends on the applying this same solution to other instances of it.
For example, the factorial of 4 can also be defined as the factorial of 3 multiplied by 4 and so on.
This means the factorial of a number can be defined in terms of itself:
factorial(5) = factorial(4) * 5
factorial(5) = factorial(3) * 4 * 5
factorial(5) = factorial(2) * 3 * 4 * 5
factorial(5) = factorial(1) * 2 * 3 * 4 * 5
factorial(5) = factorial(0) * 1 * 2 * 3 * 4 * 5
factorial(5) = 1 * 1 * 2 * 3 * 4 * 5
In a nutshell, when a function calls itself we can say we have recursion.
Thinking About Recursion Effectively
When I'm thinking about recursion I like to imagine multiple branches of execution deriving of a first execution and then bubbling up results back to the root call.
In the previous factorial example, we can see that multiple calls derive from the first one until we reach a definition that already exists by itself (in this case, the factorial of 0, which is one). Then, the result of this definition is returned (bubbles up) so that we can do another operation with it and return a value again, repeating this process all the way back to provide the result to the "root" call.
If we had to represent the calls a factorial function does when it is invoked passing 5 as an argument, it would look like this:
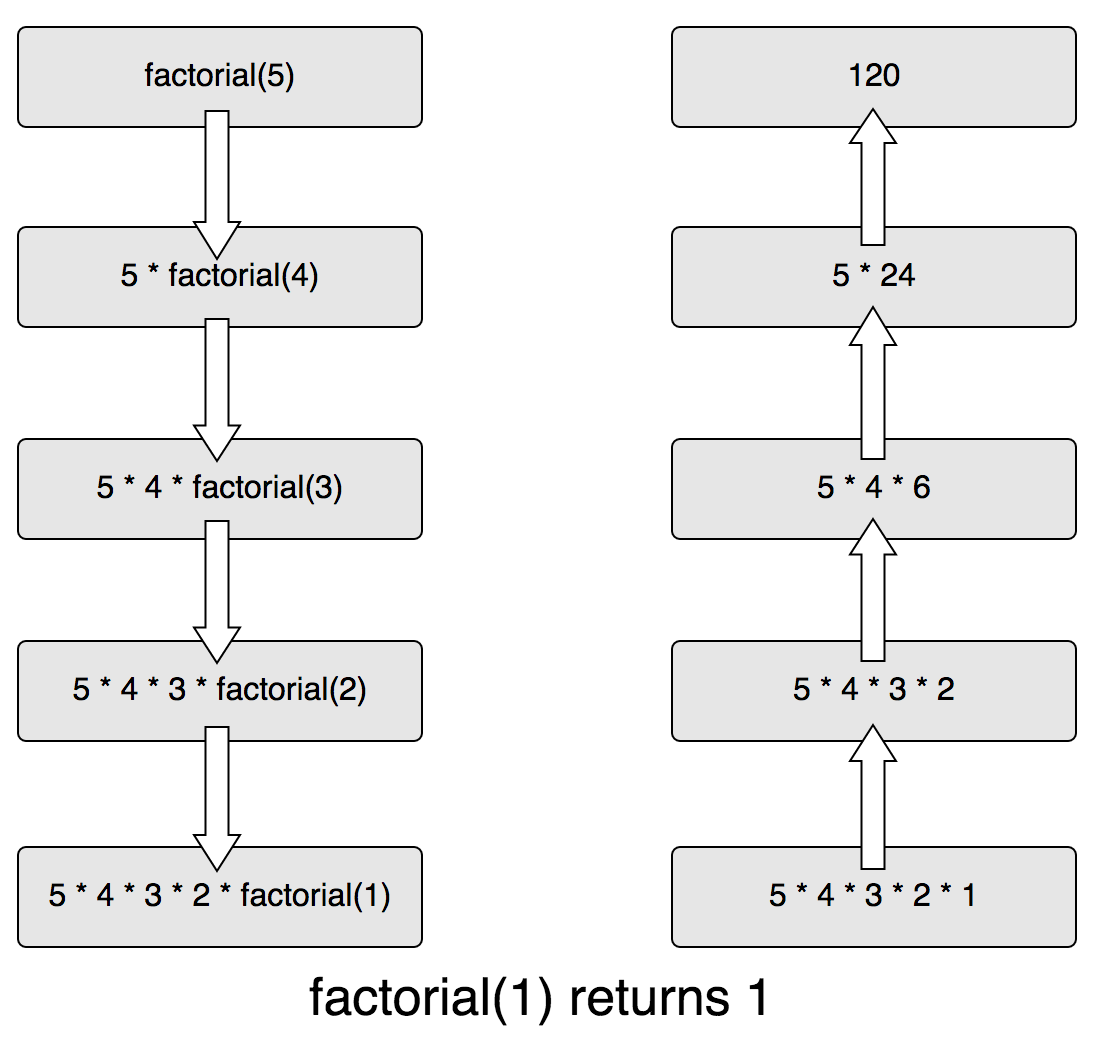
By doing a parallel with compilers' theory, this looks very much like what happens when we use a context-free grammar to derive sentences until we reach terminal values.
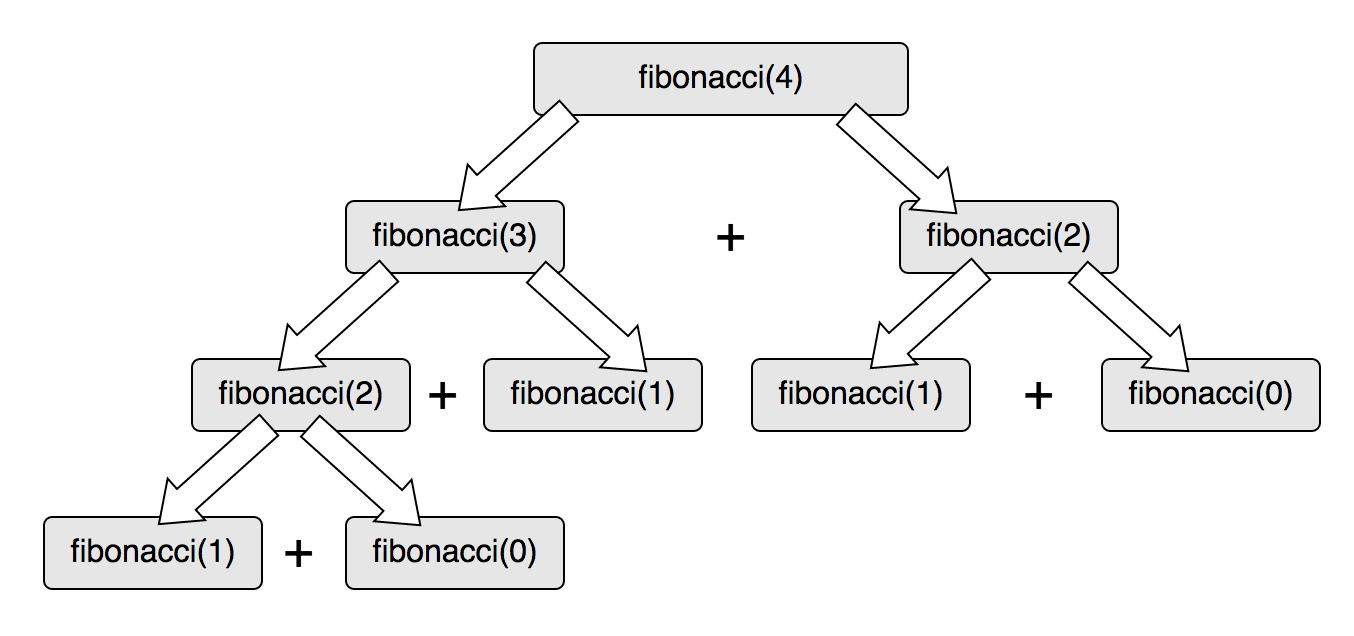
This might seem abstract at first, but let me demonstrate visually how this process of thought works in another way by dissecting a call to a function that calculates the Nth number in the Fibonnacci Sequence.
This is the code for our Fibonacci function:
// N is the Nth fibonacci
function fibonacci(n) {
if (n < 2) {
return 1
} else {
return fibonacci(n - 2) + fibonacci(n - 1)
}
}
Basically, each call to the Fibonacci function generates two more calls, which may also call themselves until they reach a number that is smaller than 2 (because the Fibonacci sequence starts with 1 and 1, generating two when they're summed).
When we reach a number smaller than two we return this result so that we can feed the calls above it, bubbling up results all the way up to the root call.
As the image below clearly demonstrates, when calling factorial(4), we end up deriving calls from it until we reach a "self-contained" definition (a "base case") which in this case are the first two numbers in the Fibonacci sequence: 1 (0th) and 1 (1st).
Since each recursive call depends on the result of another two recursive call (unless the value passed is smaller than 2 and therefore a "base case"), we start returning values from the leaves (1) and then summing them in order to feed the call above.
As you could notice in the examples above, we can have linear recursion (when there is a single branch of recursive calls, such as in the factorial example) and branching recursion (when there is more than one branch of recursive calls, such as in the Fibonacci example).
When thinking about recursion, there are two main things you need to think about:
- Defining an exit condition, an atomic definition that exists by itself (also called a "base case").
- Defining which part of the algorithm is recursive.
After you have defined an exit condition it is easy to determine when a function should call itself again and what it should do with the results.
If you want to read more about practical and fun applications of recursion, take a look at how trees and graph-related algorithms work.
Recursion and the Call Stack
Commonly, when using recursion, we end up stacking functions one on top of the other, because they might depend on the result of the previous invocation of itself.
If you want to get a good understanding of how a call stack works or how to read a stack trace, take a look at this post.
In order to demonstrate what the call stack looks like when we have recursion, let's use a simple recursive factorial function as an example.
This is its code:
function factorial(n) {
if (n === 0) {
return 1
}
return n * factorial(n - 1)
}
Now, let's call it and check the factorial of 3.
As you might remember from the previous example, the factorial of 3 consists of getting factorial(2), factorial(1) and factorial(0) and multiplying them. This means that a simple call to retrieve the factorial of 3 does three more calls to the factorial function.
Each one of these calls pushes a new frame onto the call stack, so it might look like this when all of them are stacked:
factorial(0) // The factorial of 0 is 1 by definition (base case)
factorial(1) // This call depends on factorial(0)
factorial(2) // This call depends on factorial(1)
factorial(3) // This first call depends on factorial(2)
Now, let's add a call to console.trace in order to see the current frames in the stack whenever the factorial function is called.
Your code should look like this now:
function factorial(n) {
console.trace()
if (n === 0) {
return 1
}
return n * factorial(n - 1)
}
factorial(3) // Let's call the factorial function and see what happens
Now let's run this code and analyze each one of the printed call stacks.
This is the first one:
Trace
at factorial (repl:2:9)
at repl:1:1 // Ignore everything below this line, it's just implementation details
at realRunInThisContextScript (vm.js:22:35)
at sigintHandlersWrap (vm.js:98:12)
at ContextifyScript.Script.runInThisContext (vm.js:24:12)
at REPLServer.defaultEval (repl.js:313:29)
at bound (domain.js:280:14)
at REPLServer.runBound [as eval] (domain.js:293:12)
at REPLServer.onLine (repl.js:513:10)
at emitOne (events.js:101:20)
As you can see, the first call stack contains only the first call to the factorial function, which is factorial(3), but now things will start to get interesting:
Trace
at factorial (repl:2:9)
at factorial (repl:7:12)
at repl:1:1 // Ignore everything below this line, it's just implementation details
at realRunInThisContextScript (vm.js:22:35)
at sigintHandlersWrap (vm.js:98:12)
at ContextifyScript.Script.runInThisContext (vm.js:24:12)
at REPLServer.defaultEval (repl.js:313:29)
at bound (domain.js:280:14)
at REPLServer.runBound [as eval] (domain.js:293:12)
at REPLServer.onLine (repl.js:513:10)
Here we have another call to the factorial function right on top of the last one. This one is factorial(2).
Then this is the stack when we call factorial(1):
Trace
at factorial (repl:2:9)
at factorial (repl:7:12)
at factorial (repl:7:12)
at repl:1:1
at realRunInThisContextScript (vm.js:22:35)
at sigintHandlersWrap (vm.js:98:12)
at ContextifyScript.Script.runInThisContext (vm.js:24:12)
at REPLServer.defaultEval (repl.js:313:29)
at bound (domain.js:280:14)
at REPLServer.runBound [as eval] (domain.js:293:12)
As you can see, it added another call on top of the previous ones.
And, finally, the call stack when we reach factorial(0):
Trace
at factorial (repl:2:9)
at factorial (repl:7:12)
at factorial (repl:7:12)
at factorial (repl:7:12)
at repl:1:1
at realRunInThisContextScript (vm.js:22:35)
at sigintHandlersWrap (vm.js:98:12)
at ContextifyScript.Script.runInThisContext (vm.js:24:12)
at REPLServer.defaultEval (repl.js:313:29)
at bound (domain.js:280:14)
As I've said at the beginning of this section, the first call to factorial(3) needed to call factorial(2), factorial(1) and factorial(0). This is why we have four entries for the factorial function in our stack.
Now you're probably seeing the problem we might face when having too much recursion: the call stack gets too big and we end up having a Stack Buffer Overflow. This happens when we try to add another entry to the call stack after it has reached its limit.
If you want to calculate how many frames you can have in your stack depending on which environment you're running your JavaScript code into, I highly recommend you to try this cool method posted by Dr. Axel Rauschmayer (a guy I'm a big fan of).
Proper Tail Calls (PTC)
Proper tail calls should have been implemented when ES6 came out, but it is not available yet in all major JS engines due to reasons I'll explain later in this post.
Proper tail calls allow us to avoid blowing the stack when doing recursive calls. However, in order to make proper tail calls, we need to actually have a tail call in the first place.
But what is a tail call?
Tail calls are functions that can be executed without growing the stack. They're always the last thing to be done and evaluated before the return and the return value of this called function is returned by the calling function. The calling function also cannot be a generator function.
If you are into compilers' theory and this kind of hardcore (a.k.a. awesome) stuff you can read the formal definition in the ECMA spec.
In order to demonstrate how proper tail calls work we need to refactor our old factorial function and make it tail recursive:
// If total is not provided we assign 1 to it
function factorial(n, total = 1) {
if (n === 0) {
return total
}
return factorial(n - 1, n * total)
}
Now the last thing this function will do will be returning the result of calling itself and nothing more, which makes it tail recursive.
As you might have noticed we're now passing two arguments to it: the number we want to calculate the next factorial of (n - 1) and the accumulated total, which is n * total.
Now we don't need to necessarily get to the leaves of the derivate calls anymore (as we did in the previous example) since we have all the values we need in order to fulfill the current state (the accumulated value and the next factorial we should calculate).
Let's analyze how this function is able to do that without stacking multiple recursive calls.
This is what happens when we call factorial(4):
- A call to
factorialis added to the top of the stack - Since
4is not 0 (the base case) we determine the next number we need to calculate (3) and the current accumulated value (4 * total (which is one by default)) - Now when calling
factorialagain it will receive every piece of data it needs to do its processing: the next factorial to calculate and the accumulated total. Due to this, we don't need the previous stack frame anymore, so we can just pop that frame out of our stack and add the newfactorial(3, 4)call. - This call is again bigger than 0, so we get the next factorial and multiply the accumulated value (
4) by the current value (3). - The previous call is not needed anymore (again) so we can pop that frame and call
factorialagain, passing it2and12. One more time we will update the total value to24and get the factorial of1. - The previous frame gets removed from the stack and we multiply
24(the total) by1and try to get the factorial of0. - Finally, the factorial of
0returns the accumulated total, which is24(which is the factorial of 4)
In a nutshell, this is what happens:
factorial(4, 1) // 1 is the default value when nothing gets passed
factorial(3, 4) // This call does not need the previous one, it has all the data it needs
factorial(2, 12) // This call does not need the previous one, it has all the data it needs
factorial(1, 24) // This call does not need the previous one, it has all the data it needs
factorial(0, 24) // -> Returns the total (24) and also does not need the previous one
Now, instead of stacking n frames, we just need to stack 1, since the subsequent calls don't depend on the previous ones, which makes our new factorial function have a memory complexity of O(1) instead of O(N).
Using Proper Tail Calls on Node
If you add a console.trace call to the function above and call factorial(3) in order to see the calls that get stacked, like this:
function factorial(n, total = 1) {
console.trace()
if (n === 0) {
return total
}
return factorial(n - 1, n * total)
}
factorial(3)
You will see that it still stacks calls to the factorial function even though we can say this function is tail recursive:
// ...
// These are the last two calls to the `factorial` function
Trace
at factorial (repl:2:9) // Here we have 3 calls stacked
at factorial (repl:7:8)
at factorial (repl:7:8)
at repl:1:1 // Implementation details below this line
at realRunInThisContextScript (vm.js:22:35)
at sigintHandlersWrap (vm.js:98:12)
at ContextifyScript.Script.runInThisContext (vm.js:24:12)
at REPLServer.defaultEval (repl.js:313:29)
at bound (domain.js:280:14)
at REPLServer.runBound [as eval] (domain.js:293:12)
Trace
at factorial (repl:2:9) // The last call added one more frame to our stack
at factorial (repl:7:8)
at factorial (repl:7:8)
at factorial (repl:7:8)
at repl:1:1 // Implementation details below this line
at realRunInThisContextScript (vm.js:22:35)
at sigintHandlersWrap (vm.js:98:12)
at ContextifyScript.Script.runInThisContext (vm.js:24:12)
at REPLServer.defaultEval (repl.js:313:29)
at bound (domain.js:280:14)
In order to have access to proper tail calls on Node, we must enable strict mode by adding 'use strict' to the top of our .js file and then run it with the --harmony_tailcalls flag.
In order for that flag to be able to improve our factorial function, our script should look like this:
'use strict'
function factorial(n, total = 1) {
console.trace()
if (n === 0) {
return total
}
return factorial(n - 1, n * total)
}
factorial(3)
Let's run it with:
$ node --harmony_tailcalls factorial.js
When running that code again, these are the stack traces we get back:
Trace
at factorial (/Users/lucasfcosta/factorial.js:4:13)
at Object.<anonymous> (/Users/lucasfcosta/factorial.js:12:1)
at Module._compile (module.js:571:32)
at Object.Module._extensions..js (module.js:580:10)
at Module.load (module.js:488:32)
at tryModuleLoad (module.js:447:12)
at Function.Module._load (module.js:439:3)
at Module.runMain (module.js:605:10)
at run (bootstrap_node.js:420:7)
at startup (bootstrap_node.js:139:9)
Trace
at factorial (/Users/lucasfcosta/factorial.js:4:13)
at Object.<anonymous> (/Users/lucasfcosta/factorial.js:12:1)
at Module._compile (module.js:571:32)
at Object.Module._extensions..js (module.js:580:10)
at Module.load (module.js:488:32)
at tryModuleLoad (module.js:447:12)
at Function.Module._load (module.js:439:3)
at Module.runMain (module.js:605:10)
at run (bootstrap_node.js:420:7)
at startup (bootstrap_node.js:139:9)
Trace
at factorial (/Users/lucasfcosta/factorial.js:4:13)
at Object.<anonymous> (/Users/lucasfcosta/factorial.js:12:1)
at Module._compile (module.js:571:32)
at Object.Module._extensions..js (module.js:580:10)
at Module.load (module.js:488:32)
at tryModuleLoad (module.js:447:12)
at Function.Module._load (module.js:439:3)
at Module.runMain (module.js:605:10)
at run (bootstrap_node.js:420:7)
at startup (bootstrap_node.js:139:9)
Trace
at factorial (/Users/lucasfcosta/factorial.js:4:13)
at Object.<anonymous> (/Users/lucasfcosta/factorial.js:12:1)
at Module._compile (module.js:571:32)
at Object.Module._extensions..js (module.js:580:10)
at Module.load (module.js:488:32)
at tryModuleLoad (module.js:447:12)
at Function.Module._load (module.js:439:3)
at Module.runMain (module.js:605:10)
at run (bootstrap_node.js:420:7)
at startup (bootstrap_node.js:139:9)
As you can see, we're not stacking more than one call to factorial at a time, because every time we call it, we don't need the previous frame anymore.
A good tip to create tail recursive functions is to pass all the "state" needed for the next call in order to be able to drop the next frame. Since you can't always do that inside a single function, you can also think about how viable it is to create a nested function, which can be tail recursive.
You should also keep in mind that proper tail calls do not necessarily make your code run faster. Actually, most of the time, it just makes it slower.
However, besides allowing you to use less memory to store your stack, when using proper tail calls you also get locally allocated objects and end up needing less memory to run your recursive functions too, because since you don't need any variables inside the current frame for the next recursive call, you allow the garbage collector to collect every object allocated inside the current frame, while in "non-tail-recursive" functions you would need to do allocations each time the recursive function was called, due to the fact that all the frames would be kept into the stack until the last recursive call (the one that is the "base case") returns.
Tail Call Optimization (TCO)
Differently to what happens with proper tail calls, tail call optimization actually improves the performance of tail recursive functions and makes running them faster.
Tail call optimization is a technique used by the compiler to transform your recursive calls into a loop using jumps.
Since we already know how tail recursive functions work, it becomes really easy to explain how tail call optimization works.
Let's take the factorial function we have used previously and simulate what would probably happen with it if we had tail call optimization enabled in our JavaScript engines.
This is our starting code:
function factorial(n, total = 1) {
if (n === 0) {
return total
}
return factorial(n - 1, n * total)
}
Given that there is code here that will be repeated until the exit condition ("base case") is met, we can put it inside a label and jump straight to it instead of trying to call a function again. So our code might become something like this:
function factorial(n, total = 1) {
LABEL:
if (n === 0) {
return total
}
total = n * total
n = n - 1
goto LABEL
}
This means that tail call optimization is not the same as having proper tail calls!
Disadvantages of Having Proper Tail Calls and Tail Call Optimization
As you could see in the examples above, having proper tail calls implies in not "saving" the history of all the function calls to our stack, which makes it more difficult to track bugs by reading the stack trace, since we don't have information about all the calls that lead to the current situation.
This affects both console.trace statements and also the Error.stack property we talked about in this post I've mentioned before.
A possible solution to this is having a "Shadow Stack" in development environments.
A Shadow Stack works just like a "second stack". While the normal stack does not keep frames around when proper tail recursive calls are made, these calls get pushed into our "shadow stack" so that we can use it for debugging purposes and still avoid pushing these frames into the execution stack.
However, as you might imagine, there's a lack of consolidated and easy-to-use tools for this and it also requires more memory to store all these frames in another place (which might not be a problem in a development environment).
Finally, using a shadow stack still does not solve the problem of the Error.stack property if we have Tail Call Optimization because when that happens we start using goto statements and not adding any frames to the stack trace. This means that when an error is created it might not have the function it was inside in the stack because we got to that statement by jumping to a label and not by calling that function as we would normally do.
If you're curious about that, take a look at this excellent blog post by Michael Saboff about how WebKit handles tail calls.
Syntactic Tail Calls (STC)
Syntactic tail calls are a way of indicating to the compiler when proper tail calls and tail call optimization are wanted.
This way we could enable developers to choose whether they want this feature or not. It's basically just a really explicit opt-in.
This allows us to manage the complexity of the elided stack frames and also allows new possibilities for "less invasive solutions (or no solutions at all)" (as the proposal itself says).
When it comes to the syntax there are some alternatives being studied and you can see them right here.
Right now this is an stage 0 proposal.
Related Material
- V8 Team blog post which also talks about tail calls
- Checking whether a function is in a tail position by Dr. Axel Rauschmayer
- ECMAScript 6 Proper Tail Calls in WebKit by Michael Saboff
- The Syntactic Tail Calls Proposal by Brian Terlson
- Issue about Tail call Optimization (TCO) in ES6 & Node.js by Mr. Rod Vagg
- ES6 tail calls controversy issue by Juriy Zaytsev
Get in touch!
If you have any doubts, thoughts or if you disagree with anything I've written, please share it with me in the comments below or reach me at @thewizardlucas on Twitter. I'd love to hear what you have to say.
Thanks for reading!
Subscribe
Get an email when I publish a new post. I'll never send you spam.
